안녕하세요, 여행벌입니다.
저번 포스팅에 이어서
"혈청 Micro-RNA 데이터와 기계학습을 통한 암종의 다중 분류"
준비 과정에 대해서 포스팅해보겠습니다.
[원본데이터 학습진행]
먼저, 원본데이터를 가지고 학습을 진행했습니다. 학습 과정은 다음과 같습니다.
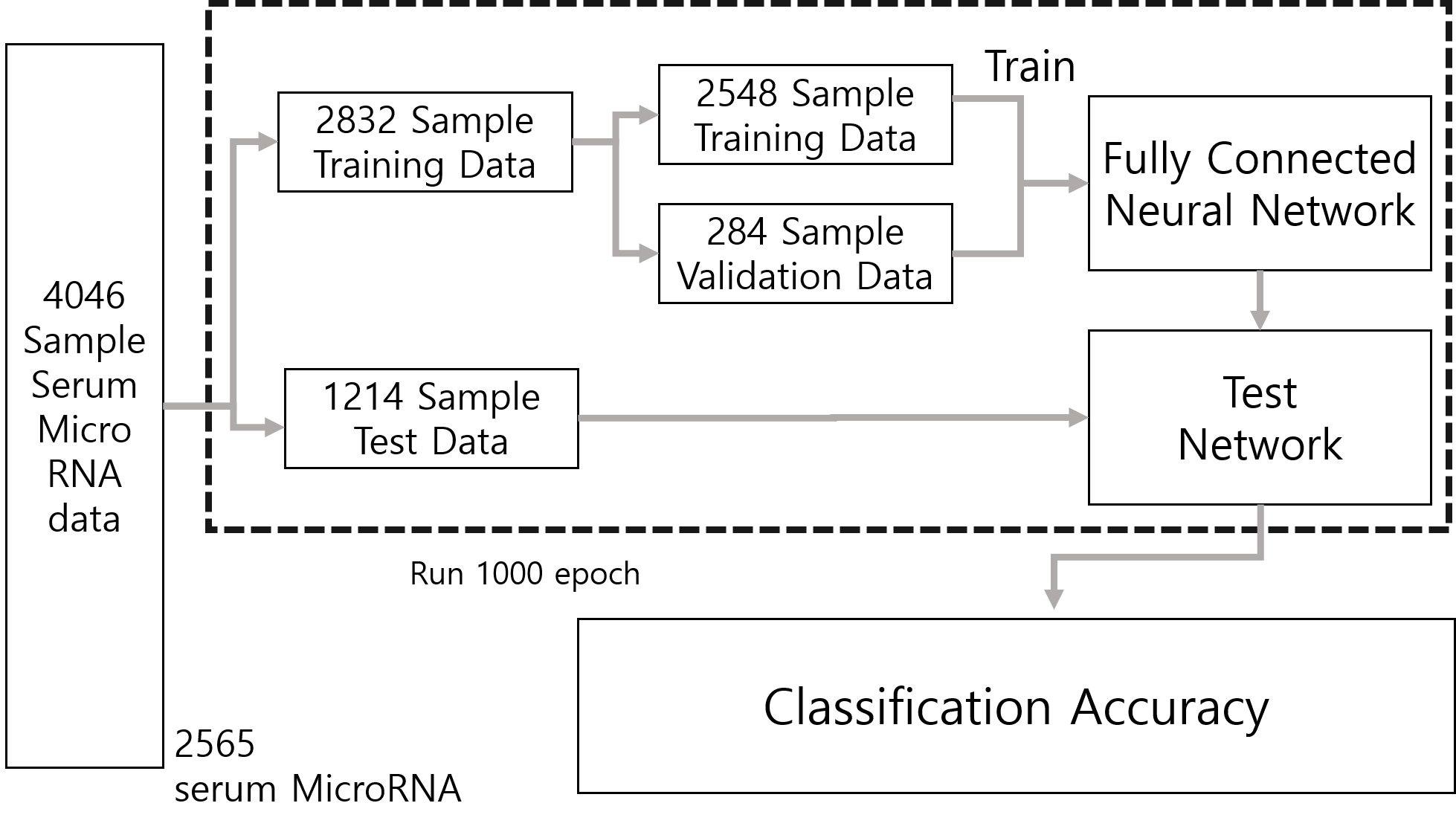
7 : 3 의 비율로 Training Data와 Test Data를 나누고 다시 Training Data를 9 : 1의 비율로 Training Data와 Validation Data로 나눴습니다. 그 후, 학습률 0.01 로 500 epoch, 학습률을 0.001로 낮춰 500 epoch 총 1000 epoch 동안 학습을 진행했습니다. Output Layer는 log softmax를 활성화 함수로 사용하고, 나머지 layer에서는 ReLU 활성화 함수를 이용했습니다. 완전 연결 계층의 경우는 드랍아웃을 추가적으로 사용했고, 손실함수는 Cross entropy 함수를 이용했습니다. 최종적으로 평균 90.38%의 정확도를 얻었습니다.
# 데이터 나누기
train_data, test_data, train_target, test_target = train_test_split(data, target, test_size = 0.3)
train_data, validation_data, train_target, validation_target = train_test_split(train_data, train_target, test_size = 0.1)#신경망구현
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(2565,1280)
self.fc2 = nn.Linear(1280,640)
self.fc3 = nn.Linear(640,320)
self.fc4 = nn.Linear(320,12)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = F.dropout(x, training=self.training)
x = self.fc4(x)
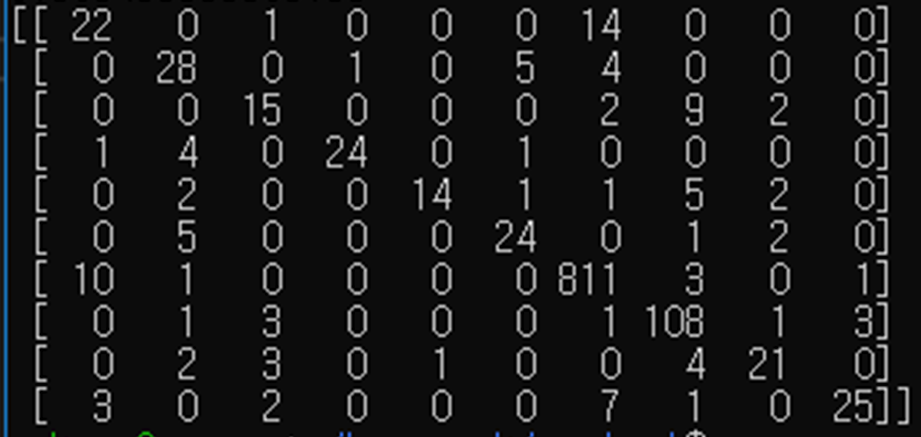
return F.log_softmax(x)여러 번의 학습 중 하나의 예시에 대한 정답 테이블과 그래프입니다.
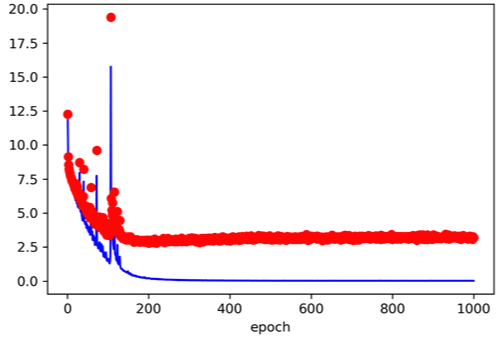
Training Data / Validataion Data 의 손실값에 대한 그래프입니다. (빨간색 : Validation 파란색 : Training Data)
Training Data / Validataion Data 의 정확도에 대한 그래프입니다. (빨간색 : Validation 파란색 : Training Data)

위의 그래프를 통해 학습이 제대로 이루어지지 않고 있는 것을 알 수 있고, 이는 비암환자 클래스가 압도적으로 많은 데이터 수를 가지고 있기 때문에 오버피팅 된 것으로 판단했습니다.
따라서, SMOTE 알고리즘을 통해 오버샘플링을 진행했고 각 클래스 별로 500개의 Data로 균일하게 크기를 맞춰 학습을 진행해봤습니다. 하지만 오히려 정확도가 60%까지 떨어지는 결과가 나왔고, 언더샘플링을 통해 크기가 100개 이상인 클래스를 모두 크기를 100으로 맞춰주고 학습을 진행한 경우에도 정확도가 7~ 80%까지 떨어지는 결과가 나왔습니다.
최종적으로 랜덤추출 오버샘플링을 통해 클래스 별로 Data 크기를 맞춰서 학습을 진행했습니다.
랜덤추출 오버샘플링 코드는 다음과 같습니다.
ninput = 301
dummy_data = pd.DataFrame()
for i in range(1,ninput):
row = random.randrange(0,115)
dummy_data = dummy_data.append(data1.iloc[row])
dummy_data.shapedata1은 유방암으로 원본 데이터는 115명에 대한 데이터입니다. 데이터를 300개로 키우기 위해 랜덤하게 데이터를 계속 추출합니다. 다음과 같은 과정을 모든 클래스에 대해서 진행하면 랜덤추출 오버샘플링을 통해 클래스 별로 Data 크기를 맞춘 데이터를 얻을 수 있습니다.
[시뮬레이션 결과]
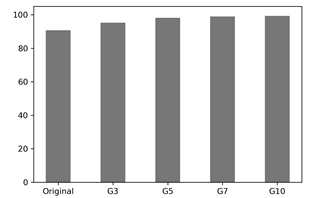
각 암종별 데이터 수를 동일하게 300(G3), 500(G5), 700(G7), 1000(G10)으로 데이터를 각 2번 반복 생성하였습니다. 생성 방법은 무작위 추출을 통한 오버샘플링 기법을 활용하였습니다. 그 후 데이터별로 10번의 학습을 진행했습니다. 원본 데이터로 학습시킨 결과는 최대 91.65%, 평균 90.38% 정확도인데 반해서 오버샘플링 기법을 활용한 결과, 최대 99.50%의 정확도를 얻었습니다.
[결론]
제안된 모델은 9종류의 암종과 건강한 사람을 100%에 가까운 정확도로 구분합니다. 한 가지 우려되는 제한사항은 데이터에 대한 접근성으로 RNA 데이터가 세포 속에 있기 때문에 다른 데이터에 비해 비교적 채취하기가 어렵습니다. 하지만 microRNA가 암과 연관이 있음이 밝혀지고 이를 빠르고 효과적으로 얻기 위한 연구가 진행되고 있습니다. 현재는 microRNA가 혈청과 혈장을 타고 순환하는 사실이 밝혀지면서 혈중 microRNA 연구가 가속화되고 있습니다. 가까운 시일 내에 mircoRNA 데이터와 제안된 모델로 암을 진단하여 암의 오진율 및 사망률 감소를 기대합니다.
학습을 진행하는 과정은 밤새 연구실 서버에서 돌렸기 때문에 오히려 어렵지 않았습니다.
하지만 더 좋은 신경망을 찾기 위해서 층도 늘려보고 구조를 바꿔보고 하는 과정이 어려웠던 것 같습니다.
다음 포스팅에서는 학술 대회에서 교수님들께 받은 질문과 한계점에 대해서 포스팅해보도록 하겠습니다.
'Others' 카테고리의 다른 글
| [STS] 다크 테마 적용하기 (0) | 2020.07.02 |
|---|---|
| [ 구글 크롬 테마 바꾸기 feat 다크모드. ] - travelbeeee (0) | 2020.03.26 |
| [한국지능시스템학회 2019 추계학술대회] 논문 준비과정(1) (0) | 2019.11.18 |
| [차근차근Pytorch] 기본 명령어 (0) | 2019.09.20 |
| [차근차근Pytorch] Windows10 환경설정하기 (0) | 2019.09.20 |


