안녕하세요, 여행벌입니다.
오늘은 문자열을 검색할 때 사용하는 강력한 알고리즘인 KMP 알고리즘에 대해서 포스팅해보겠습니다.
[ 문자열 검색 ]
문자열 검색이란 주어진 긴 문자열(H)에서 문자열(N)을 부분 문자열로 포함하는지 확인하고, 포함한다면 N과 일치하는 부분 문자열의 시작 위치를 찾는 문제를 문자열 검색 문제라고 합니다.
예를 들어, "ABCDABCABACBABC" 에서 "ABC" 문자열을 찾는 경우를 생각해보겠습니다.

가장 간단하고 확실한 방법은 H의 모든 지점에서 N과 하나씩 비교해나가면서 같다면 저장하고, 아니라면 다시 다음 칸으로 이동해서 같은 과정을 반복하는 방법입니다.
하지만, 이 방법은 H의 모든 지점에 대해서 N개 씩 문자를 비교해야되므로 O(|H| * |N|) 의 복잡도를 가지게 됩니다! 보통 N은 길이가 작지만, H는 길이가 크므로 그리 좋은 복잡도는 아닌 것을 알 수 있습니다.
KMP 알고리즘을 이용하면 O(|H| * |N|) 복잡도를 O(|H| + |N|) 으로 획기적으로 줄일 수 있습니다.
[ 사전 지식 ]
KMP 알고리즘을 다루기 전에 자주 쓰이는 용어부터 정의하고 넘어가겠습니다.
● 접두사(prefix) : 어떤 문자열 S의 0번 글자부터 a번 글자까지로 구성된 부분 문자열을 S의 접두사(prefix)라고 합니다.
● 접미사(suffix) : 어떤 문자열 S의 b번 글자부터 마지막 글자까지로 구성된 부분 문자열을 S의 접미사(prefix)라고 합니다.
ex ) 문자열 "abcde"
접두사 : a / ab / abc / abcd / abcde
접미사 : e / de / cde / bcde / abcde
● 부분 일치 테이블(partial match table)
어떤 문자열 N에 대해서, pi[ i ] := N[0 - i] 의 접두사도 되고 접미사도 되는 문자열의 최대 길이
ex ) "AABAABAC"
pi[0] = "A" 의 접두사도 되고 접미사도 되는 문자열의 최대 길이 = 0
pi[1] = "AA" 의 접두사도 되고 접미사도 되는 문자열의 최대 길이 = "A" = 1
pi[2] = "AAB" 의 접두사도 되고 접미사도 되는 문자열의 최대 길이 = 0
pi[3] = "AABA" 의 접두사도 되고 접미사도 되는 문자열의 최대 길이 = "A" = 1
pi[4] = "AABAA" 의 접두사도 되고 접미사도 되는 문자열의 최대 길이 = "AA" = 2
pi[5] = "AABAAB" 의 접두사도 되고 접미사도 되는 문자열의 최대 길이 = "AAB" = 3
pi[6] = "AABAABA" 의 접두사도 되고 접미사도 되는 문자열의 최대 길이 = "AABA" = 4
pi[7] = "AABAABAC" 의 접두사도 되고 접미사도 되는 문자열의 최대 길이 = 0
[ KMP 알고리즘 ]
KMP 알고리즘은 검색 과정에서 얻는 정보를 버리지 않고 활용해서 시간을 절약합니다. 즉, 불일치가 일어났을 때 지금까지 일치한 글자의 수를 이용해 다음으로 시도해야 할 시작 위치를 빠르게 찾아냅니다.
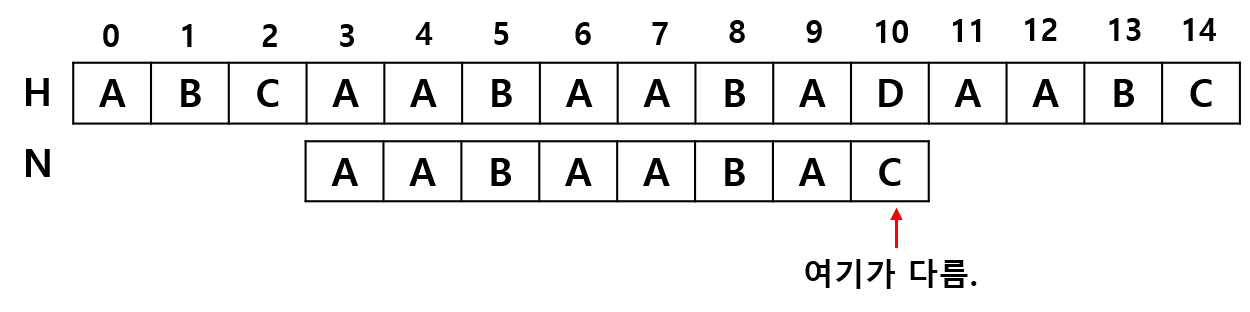
다음과 같은 경우를 생각해보겠습니다. "ABCAABAABADAABC" 에서 "AABAABAC" 를 찾는데, H[3번]에서 탐색을 진행하다 다음과 같이 마지막 부분에서만 다르다는 것을 알았다고 합시다.
이때, 일치한 부분인 S = "AABAABA"에 집중을 해봅시다.
우리는 다음과 같은 사실을 알 수 있습니다. "AABAABA"에서 접두사와 접미사가 최대한 같은 부분은 접두사 S[0번~3번글자] "AABA" 와 S[3번~6번글자] "AABA" 입니다. 이를 이용해 다음과 같은 2가지 사실을 알아낼 수 있습니다.
● "AABAABA" 에서 접두사와 접미사가 같은 부분이 S[3]부터 진행되므로 우리는 S[1], S[2] 번에 대해서 추가로 탐색할 진행할 필요 없이 그냥 3번으로 이동해서 탐색을 진행하면 됩니다. 즉, 접두사 AABA가 다시 반복되는 부분부터 탐색을 진행하면 되므로 H[4번], H[5]번에서 탐색을 진행하는 것이 아니라 H[6번]에서 탐색을 진행하면 됩니다.

위의 그림과 같은 2가지 경우는 탐색할 필요도 없이 당연히 다르다는 것을 알 수 있습니다.
● "AABAABA" 에서 3번으로 이동 후, "AABA" 4글자는 이미 같다는 것을 알고 있으므로 5번 째부터 비교를 진행해나가면 됩니다.
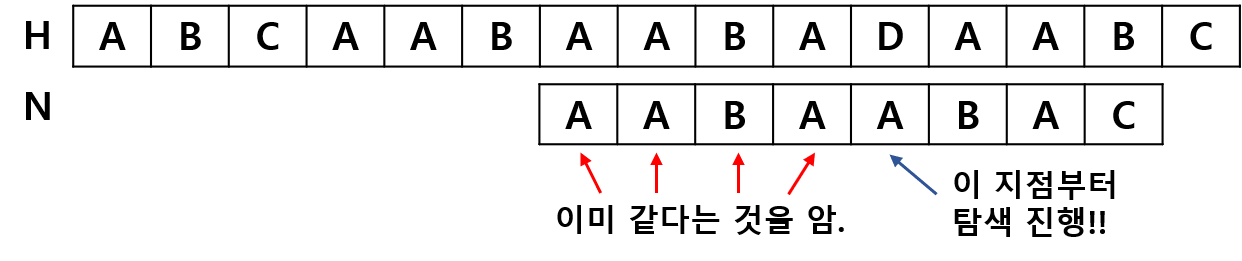
KMP알고리즘은 위와 같이 불일치가 일어났을 때, 지금까지 일치한 부분으로부터 정보를 끌어내고 그 정보를 이용해서 탐색을 더 효율적으로 진행합니다. 따라서, KMP 코드는 다음과 같습니다.
vector<int> kmp(string H, string N) {
int n = H.size(), m = N.size();
vector<int> ans;
vector<int> pi = getPartialMatch(N);
int begin = 0, matched = 0;
while (begin + m <= n) {
if (matched < m && H[begin + matched] == N[matched]) {
matched++;
if (matched == m) // 끝까지 다 일치했습니다.
ans.push_back(begin);
}
else {
if (matched == 0) begin++; // 일치한 부분이 하나도 없음 -> 시작포인트를 한 칸 앞으로
else {
begin += matched - pi[matched - 1]; // pi 배열을 이용해 다음 시작 지점으로 점프
matched = pi[matched - 1]; // pi 배열을 이용해 이미 일치하는 부분을 건너뛰고 탐색 시작
}
}
}
return ans;
}예시를 통해서 다시 한 번 KMP 작동 원리를 이해해보겠습니다.
H = "ABCABABDABABC" 에서 N ="ABABC" 를 찾는 과정을 차례대로 진행해보겠습니다.

Step 1)
begin = 0, matched = 0 에서 시작합니다.

H[0 ~ 1] 와 N[0 ~ 1] 가 "AB" 로 같으므로, matched = 2이 됩니다. ( 일치하는 문자가 2개 )
이때, "AB" 의 Pi 배열 값이 0이므로 우리는 "AB"에서 겹치는 접두사, 접미사가 하나도 없다는 것을 알 수 있습니다. 우리는 다음 탐색이 H[1] = "B" 에서 시작될건데, "AB"까지는 match가 됐으므로, H[1]="B"에서 탐색을 진행해봐야 N[0] = "A"와 match되지않는 것을 알 수 있습니다.
따라서, 다음 탐색을 굳이 H[1] 에서 진행할 필요가 없으므로 begin 을 2로 Jump 합니다.
Step 2)
begin = 2, matched = 0 에서 시작합니다.
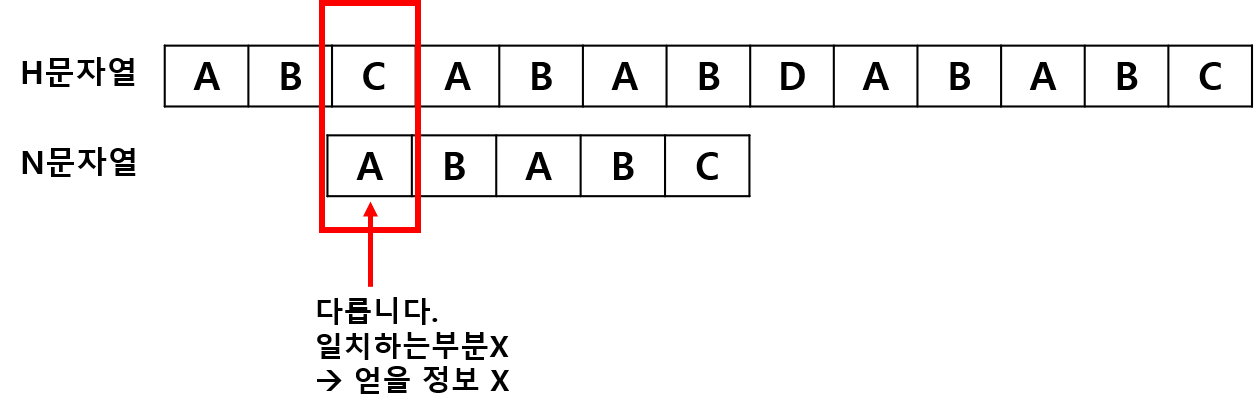
H[2] 과 N[0] 은 시작부터 다르므로 matched = 0 이 됩니다. 일치하는 문자가 하나도 없으므로, 활용할 수 있는 정보가 없고 바로 다음 칸으로 넘어가서 탐색을 진행합니다.
Step 3)
begin = 3, matched = 0 에서 시작합니다.

이번에는 "ABAB" 4글자가 일치하고, 이때 접두사와 접미사가 같은 "AB" 문자열이 존재합니다!!
어렵게 생각하지 말고, 간단하게 생각해봅시다. 일단 우리는 N 문자열을 다음 칸 부터 탐색할 필요가 없습니다. 왜냐하면 "ABAB" 이므로 접두사 "AB"를 건너뛰고 다시 시작해도 "AB"가 반복되는 것을 알 수 있습니다. 따라서, 다음 탐색을 아래 그림과 같이 2칸 건너뛰고 시작해도 됩니다!
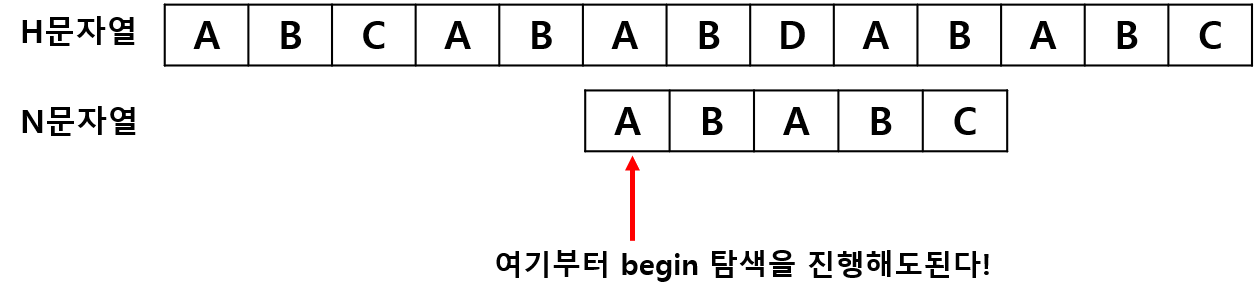
또, 우리는 2칸 건너뛰어서 탐색을 진행해도 이미 앞의 "AB"는 겹치는 것을 알고 있습니다. 따라서, 이미 matched = 2를 만족한다는 것을 알 수 있습니다! 즉, 2칸 더 건너뛰어서 탐색을 진행해도 됩니다.

이제 KMP 알고리즘이 이해가 가시나요??!
불일치가 발생할 시, 그 정보를 이용해서 위와 같이 탐색을 안해도되는 부분을 다 건너뛰고 탐색을 진행할 수 있습니다.
그렇다면, 부분 일치 테이블 pi 배열은 어떻게 구할까요?
간단한 방법은 O(|N| * |N|) 으로 접미사도 되고 접두사도 되는 문자열의 최대 길이를 구합니다.
vector<int> getPartialMatch(string N) {
int m = N.size();
vector<int> pi(m, 0);
for (int begin = 1; begin < m; begin++) {
for (int i = 0; i < m - begin; i++){
if (N[begin + i] != N[i]) break;
pi[begin + 1] = max(pi[begin + i], i + 1);
}
}
return pi
}하지만, pi 배열도 KMP 알고리즘을 이용해서 훨씬 빠르게 구할 수 있습니다. 코드는 다음과 같습니다.
vector<int> getPartialMatch(string N) {
int m = N.size();
vector<int> pi(m, 0);
int begin = 1, matched = 0;
while (begin + matched < m) {
if (N[begin + matched] == N[matched]) {
matched++;
pi[begin + matched - 1] = matched;
}
else {
if (matched == 0) begin++;
else {
begin += matched - pi[matched - 1];
matched = pi[matched - 1];
}
}
}
return pi;
}pi 배열
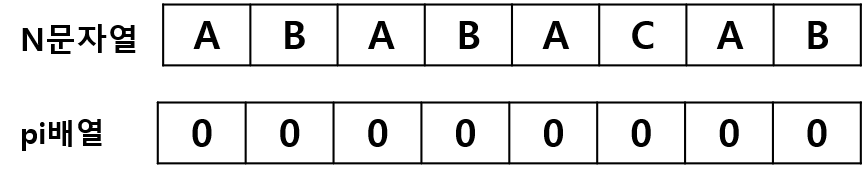
Step 1)
begin = 1, matched = 0 에서 시작하겠습니다.
N[1] 과 N[0] 은 다르고 일치한 부분이 하나도 없으므로 begin 은 다음 칸으로 이동합니다.

Step 2)
begin = 2, matched = 0 에서 시작하겠습니다.

N[2] 과 N[0] 은 "A"로 일치하므로, matched를 1 증가시키고, pi[2] = 1이 됩니다.
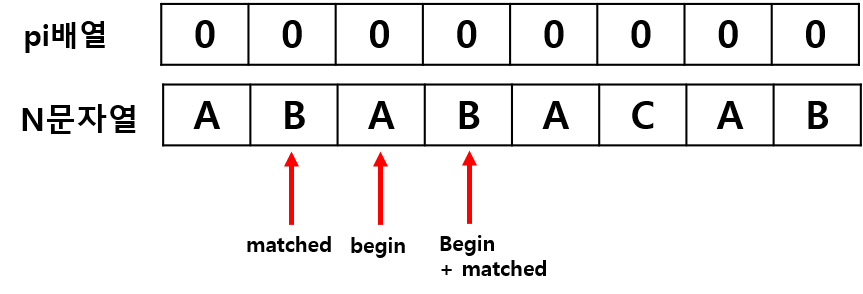
N[3] 과 N[1] 은 "B"로 일치하므로, matched를 1 증가시키고, pi[3] = 2가 됩니다.
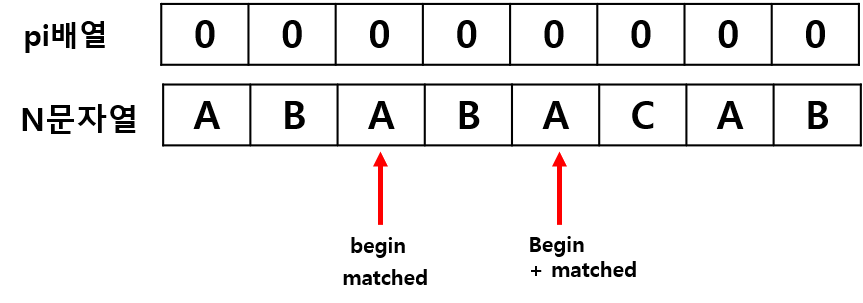
N[4] 와 N[2] 는 "A"로 일치하므로, matched를 1 증가시키고, pi[4] = 3가 됩니다.

N[5] 와 N[3] 은 "C" 와 "B"로 일치하지않습니다.
이때, 우리는 KMP 알고리즘처럼 matched 가 3이고 pi[2] 는 "ABA" 로 1이므로 begin 을 2칸 Jump하고,
matched도 1로 바로 증가시켜버려도 됩니다.
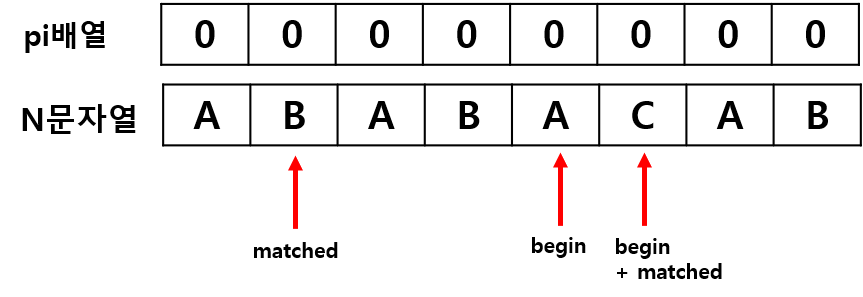
최종적으로 위 과정을 거치면 pi 배열을 O(|N| * |N|) 보다 효율적으로 얻을 수 있습니다.
즉, KMP 알고리즘을 이용해서 pi 배열을 구하면 O(|N|) 으로 시간 복잡도를 줄일 수 있습니다.
[ 최종 코드 ]
KMP 알고리즘을 이용한다면 문자열 탐색 과정의 시간 복잡도를
O(|N| * |H| + |N| * |N| ) → O(|N| + |H| + |N|) 으로 줄일 수 있습니다.
( Pi 배열을 구하는 복잡도 포함 ! )
vector<int> getPartialMatch(string N) {
int m = N.size();
vector<int> pi(m, 0);
int begin = 1, matched = 0;
while (begin + matched < m) {
if (N[begin + matched] == N[matched]) {
matched++;
pi[begin + matched - 1] = matched;
}
else {
if (matched == 0) begin++;
else {
begin += matched - pi[matched - 1];
matched = pi[matched - 1];
}
}
}
return pi;
}
vector<int> kmp(string H, string N) {
int n = H.size(), m = N.size();
vector<int> ans;
vector<int> pi = getPartialMatch(N);
int begin = 0, matched = 0;
while (begin + m <= n) {
if (matched < m && H[begin + matched] == N[matched]) {
matched++;
if (matched == m) // 끝까지 다 일치했습니다.
ans.push_back(begin);
}
else {
if (matched == 0) begin++; // 일치한 부분이 하나도 없음 -> 시작포인트를 한 칸 앞으로
else {
begin += matched - pi[matched - 1]; // pi 배열을 이용해 다음 시작 지점으로 점프
matched = pi[matched - 1]; // pi 배열을 이용해 이미 일치하는 부분을 건너뛰고 탐색 시작
}
}
}
return ans;
}
'Computer Science > Algorithm' 카테고리의 다른 글
| [알고리즘] DP(Dynamic Programming) - LIS (0) | 2020.06.19 |
|---|---|
| [알고리즘] 비트마스킹(bitmasking) 이란 (2) | 2020.06.15 |
| [알고리즘] 최단 경로 알고리즘 - 다익스트라(Dijkstra) (0) | 2020.04.29 |
| [알고리즘] 트라이(Trie) 란 (0) | 2020.04.23 |
| [알고리즘] 깊이 우선 탐색(DFS)이란 (0) | 2020.04.06 |