안녕하세요, 여행벌입니다.
오늘은 자료구조 서로소 집합(Disjoint set)과 유니온-파인드(Union-find) 기법에 대해서 다뤄보겠습니다.
Disjoint Set( 서로소 집합 )
고등학교 때, 수학 시간에 배운 집합에서 서로 공통 원소가 없는 집합을 Disjoint Set 이라 합니다. 집합을 구현하는 데는 벡터, 배열, 연결리스트를 이용할 수 있으나 보통 그중 가장 효율적인 트리 구조를 이용하여 구현합니다.
● 어떤 집합 S에 대해서 공통 원소가 없는 부분 집합들로 나눠진 원소들에 대한 자료구조
U = { 1, 2, 3, 4, 5, 6 } 일 때, A = { 1, 2 }, B = { 3, 4 } , C = { 5, 6 } 과 같은 경우를 Disjoint Set 이라고 표현한다. 쉽게 말하면 원소 N개를 서로 겹치지 않게 나눠가져 간다고 생각하면 됩니다.
Union-Find (유니온-파인드)
Disjoint Set 을 표현할 때 사용하는 알고리즘이 Union-Find 알고리즘입니다.
● Union(x, y)
- x가 속한 집합과 y가 속한 집합을 합친다. 즉, x 와 y가 속한 두 집합을 합집합하는 연산
● Find(x)
- x가 속한 집합의 대푯값을 반환한다. 즉, x가 어떤 집합에 속해 있는지 찾아주는 연산
- 트리를 이용해서 구현하므로 대푯값은 루트 노드 번호를 의미한다.
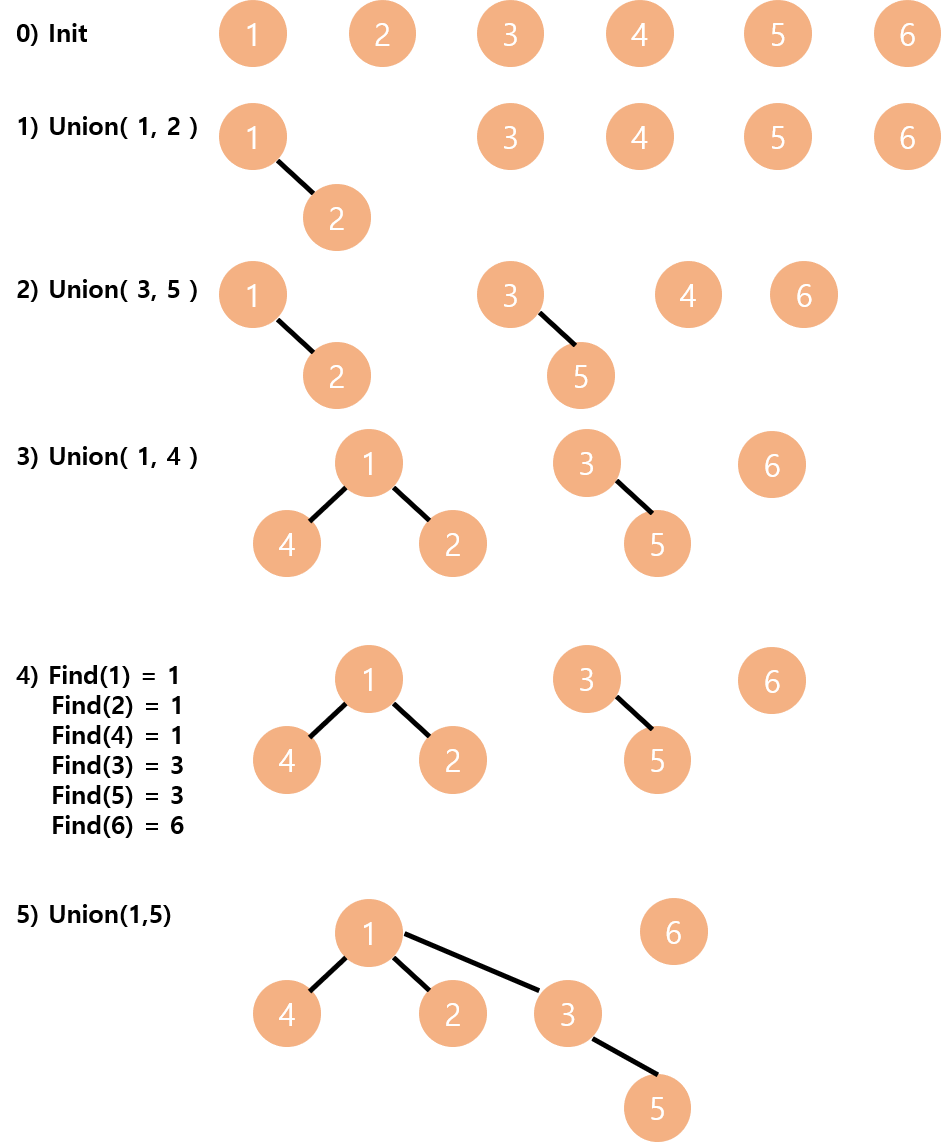
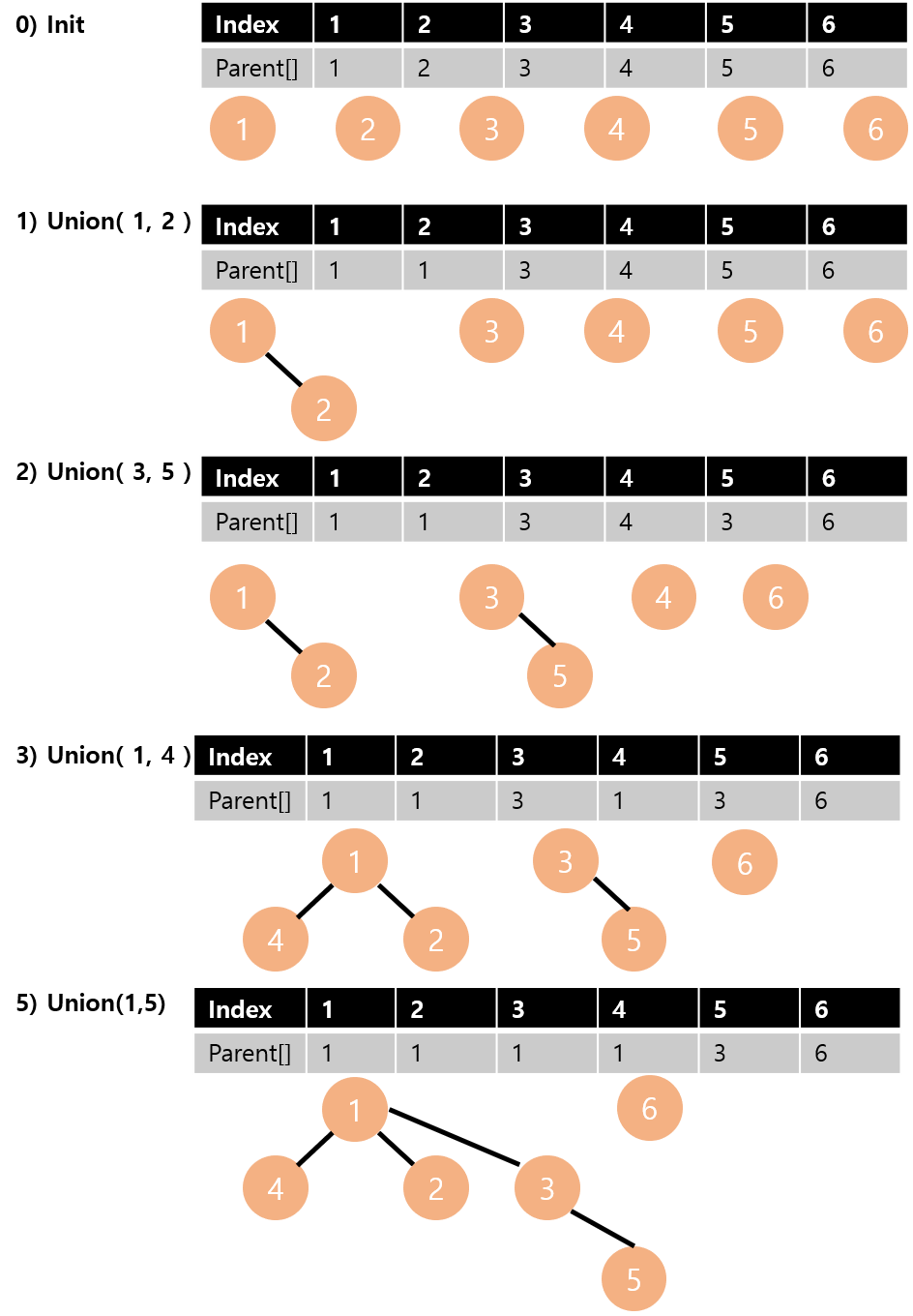
Union-Find 코드 구현
Disjoint set 은 트리 구조를 이용해서 표현한다고 위에서 언급했습니다. 따라서, parent[x] := x 노드의 부모 노드의 번호를 저장하는 배열을 먼저 선언해야 합니다. x 노드가 루트 노드인 경우에는 자기 자신의 번호를 저장합니다.
Find(x) := x가 속한 집합의 루트 노드를 반환합니다. 이때, 루트 노드는 자기 자신의 번호를 저장하고 있으므로, 재귀적으로 Find 함수를 호출하며 parent[x] 와 x가 같을 때 값을 return 해주면 됩니다
Union(x, y) := x가 속한 집합과 y가 속한 집합을 합집합 해줍니다. 따라서 먼저 x와 y 노드의 루트 노드를 find 하고 그 둘이 다르다면(다른 집합이라면) 하나의 루트 노드를 다른 루트 노드로 새롭게 갱신해주면 됩니다.
int find(int node) {
if (node == parent[node])
return node;
return find(parent[node]);
}
void merge(int node1, int node2) { // union 키워드는 이미 존재해서 보통 merge로 함수명을 선언합니다.
int parentNode1 = find(node1);
int parentNode2 = find(node2);
if (parentNode1 == parentNode2)
return;
parent[parentNode1] = parentNode2;
return;
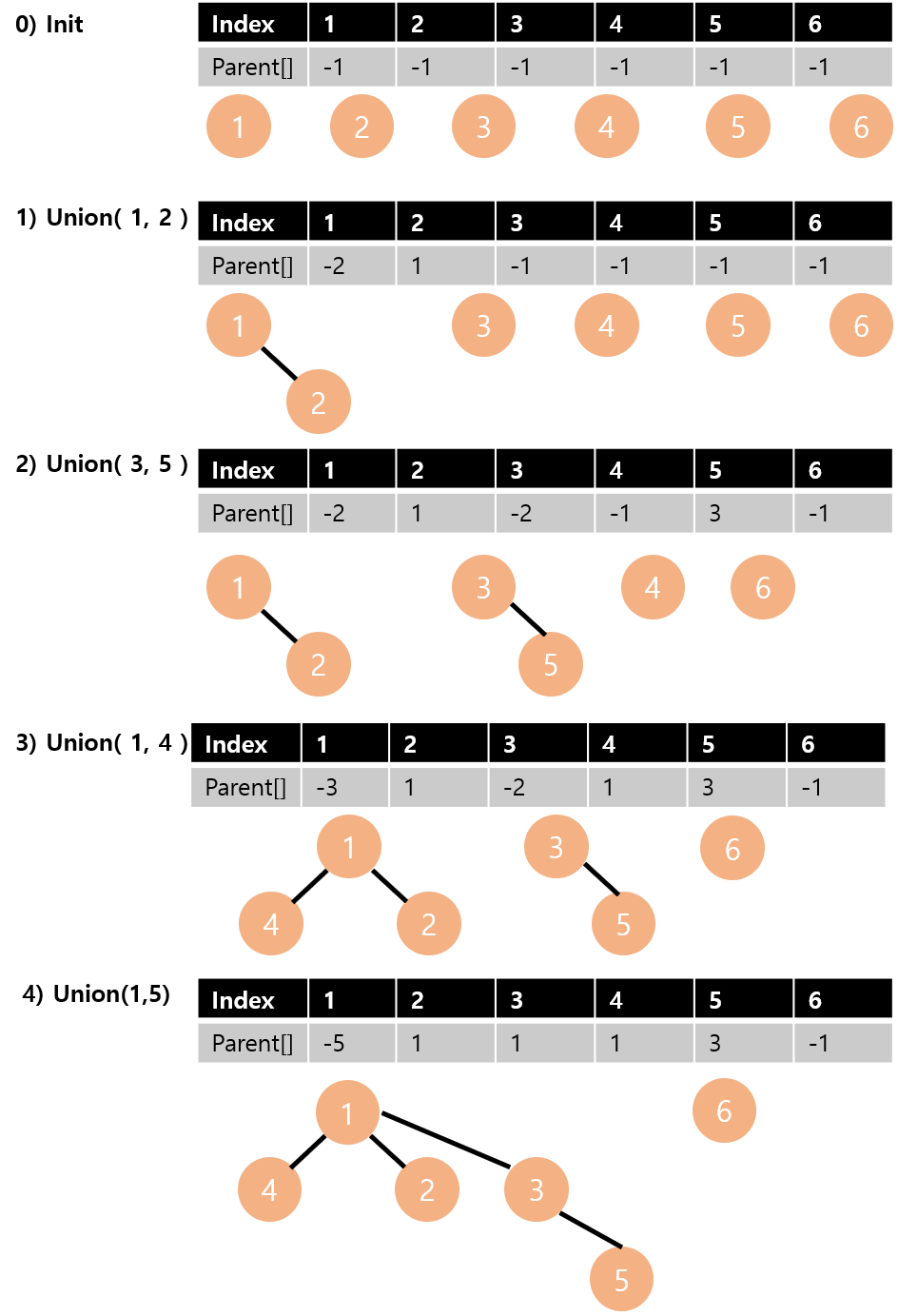
}위의 예시를 parent 배열까지 함께 나타내며 다시 보겠습니다.
Find 최적화
트리의 높이가 작아지면 작아질수록 루트 노드를 탐색하는 게 빨라집니다.
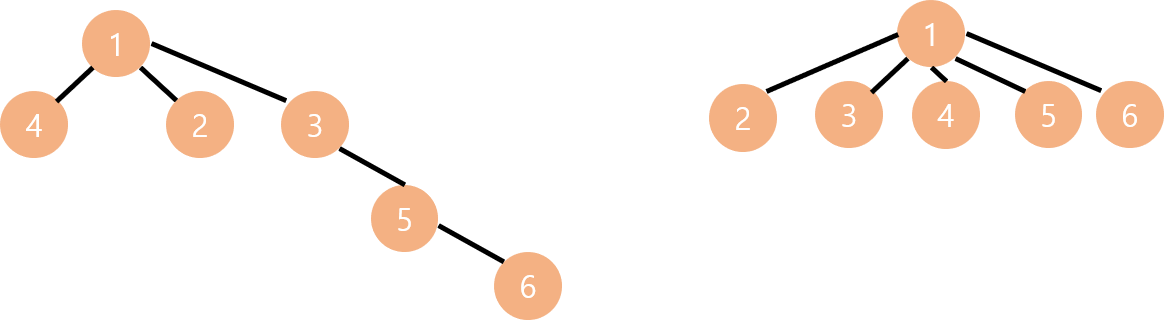
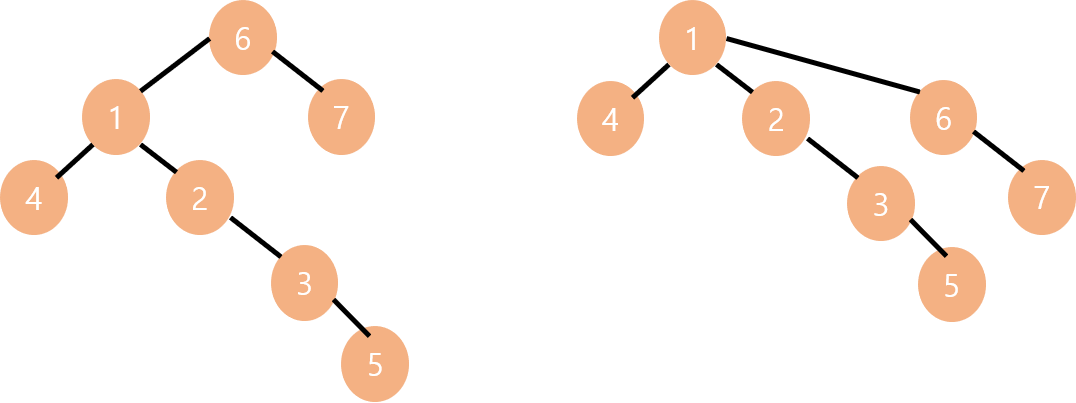
예를 들어 위와 같이 같은 Set을 나타내는 트리가 있다고 해봅시다. 이때 find(6) 을 수행하려면 왼쪽 트리는 루트 노드(1)을 찾기 위해 탐색을 여러 번 수행해야 하고, 오른쪽 트리는 단 한 번에 탐색을 끝낼 수 있습니다. 지금이야 원소가 6개뿐인 집합이라 탐색 횟수가 많이 차이 나지는 않지만, 트리가 커지면 커질수록 이 차이는 점점 커지게 됩니다. 따라서 우리는 트리의 노드들을 최대한 루트 노드와 직접 연결시켜야 합니다.
int find(int node) {
if (node == parent[node])
return node;
return parent[node] = find(parent[node]);
}find 함수를 정말 조금만 수정하면 위와 같은 문제를 해결할 수 있습니다!
parent[node] 에 find(parent[node]) 를 저장하면 됩니다! 정말 간단하죠?
예를 들어 위의 왼쪽 그림에서 find(6) 을 수행하면, parent[6] = parent[5] = parent[3] = 1; 이 됩니다. 즉, 왼쪽 그림이 오른쪽 그림으로 바로 바뀌게 되는 것을 볼 수 있습니다.
Union 최적화
Union 함수 최적화에 대해서도 생각을 해봐야 합니다. Find 함수와 마찬가지로 우리는 노드들의 높이가 낮으면 낮을수록 연산을 수행하기 좋습니다.
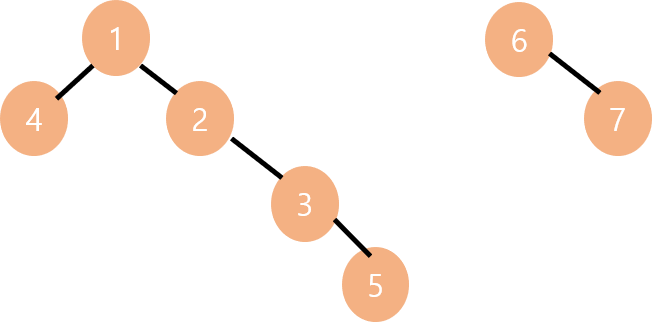
위와 같은 상황에서 2개의 집합을 Union 할 때, 왼쪽 트리를 오른쪽 트리에 합치는 경우와 오른쪽 트리를 왼쪽 트리에 합치는 경우 2가지가 존재합니다.
노드의 수가 더 많은 트리에 더 작은 트리를 합친 오른쪽의 경우가 전체 노드의 Level을 합했을 때 더 작은 값이 나오는 걸 알 수 있습니다. 즉, Union 을 더 큰 트리에 작은 트리를 합쳐가며 진행을 한다면 최적화를 할 수 있습니다.
그렇다면 트리의 Size 를 따로 저장해야되는데 어떻게 하면 트리의 Size 를 저장할 수 있을까요?
제일 간단한 방법은 Size를 저장하는 배열을 하나 더 선언하는 방법입니다.
void merge(int node1, int node2) {
int parentNode1 = find(node1);
int parentNode2 = find(node2);
if (parentNode1 == parentNode2)
return;
if (size[parentNode1] > size[paretNode2]) {
parent[parentNode2] = parentNode1;
size[parentNode1] += size[parentNode2];
}
else {
parent[parentNode1] = parentNode2;
size[parentNode2] += size[parentNode1];
}
return;
}Weighted-Union-Find
위의 방법은 parent 배열과 size 배열을 2개 선언해야 해서 메모리 낭비가 심합니다. parent 배열 하나로 트리의 크기 정보까지 저장하는 방법인 Weighted-Union-Find 방법을 소개해드리겠습니다. Weighted-Union-Find 는 parent 배열에 루트 노드라면 -(집합의크기), 루트 노드가 아니라면 부모 노드를 저장합니다. 따라서, parent 배열을 -1 로 초기화합니다. 즉, 자기가 루트 노드인 경우에는 parent 값이 음수이고 아니라면 부모 노드를 가리킵니다. 따라서, find 함수는 parent 값이 음수가 나올 때까지 진행하면 됩니다. 그리고 Union 함수는 서로 다른 집합일 경우 root 노드의 parent 값이 더 작은 경우(음수이므로 절댓값은 더 큰 경우)가 더 덩치가 큰 트리이므로 작은 트리를 큰 트리에 합쳐줍니다.
int find(int num) {
if (p[num] < 0)
return num;
return p[num] = find(p[num]);
}
void merge(int num1, int num2) {
int pNum1 = find(num1), pNum2 = find(num2);
if (pNum1 == pNum2)
return;
if (p[pNum1] <= p[pNum2]) {
p[pNum1] = p[pNum1] + p[pNum2];
p[pNum2] = pNum1;
}
else{
p[pNum2] = p[pNum1] + p[pNum2];
p[pNum1] = pNum2;
}
return;
}
이상으로 Disjoint Set(서로소 집합) & Union-Find(유니온 파인드) 포스팅을 마무리하도록 하겠습니다.
굉장히 자주 쓰이는 개념과 알고리즘으로 최적화까지 완벽하게 익혀두시면 좋을 것 같습니다!
'Computer Science > Algorithm' 카테고리의 다른 글
| [알고리즘] 깊이 우선 탐색(DFS)이란 (0) | 2020.04.06 |
|---|---|
| [알고리즘] 너비 우선 탐색(BFS) 이란 (0) | 2020.04.03 |
| [알고리즘] 합병 정렬(Merge sort) 란 - travelbeeee (0) | 2020.01.15 |
| [알고리즘] 퀵 정렬(quick sort) 란 - travelbeeee (0) | 2020.01.14 |
| [알고리즘] 셸 정렬(shell sort) 란 - travelbeeee (1) | 2020.01.14 |